PFB 局部帧缓冲设计¶
背景介绍¶
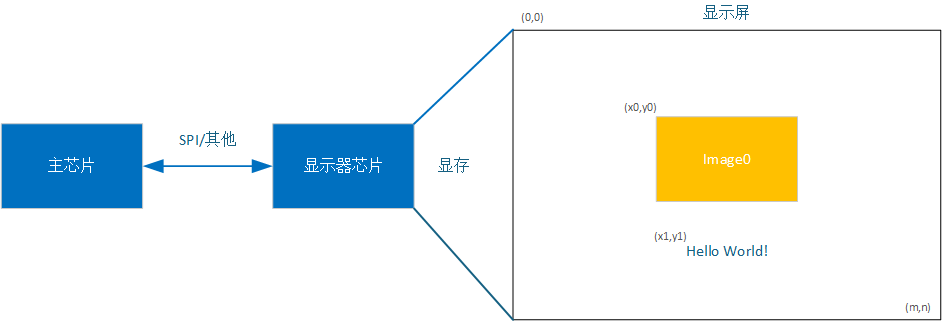
一般来说,要实现屏幕显示,就是向特定像素点写入颜色值。最简单的办法是直接通过 SPI 接口,向显示器芯片的特定显存地址写入像素点。常见显示器芯片通常会提供两类基础接口:WritePoint 和 WriteRegion。
WritePoint用于给单个像素点写入颜色,常用于绘制文字等离散内容。WriteRegion用于向一块连续区域写入像素数据,常用于绘制图片。
如下图所示,主控通过 SPI 直接向显存写入数据。调用 WriteRegion 可以在 (x0, y0) 坐标绘制整块图像;多次调用 WritePoint,配合字体像素偏移和基准坐标 (x1, y1),则可以完成文字绘制。
这种方式最大的优点是简单直接,对主控 RAM 的占用最少,因为显示缓存基本都由显示器芯片内部显存承担。很多简单项目或早期原型都可以用这种方式满足需求。
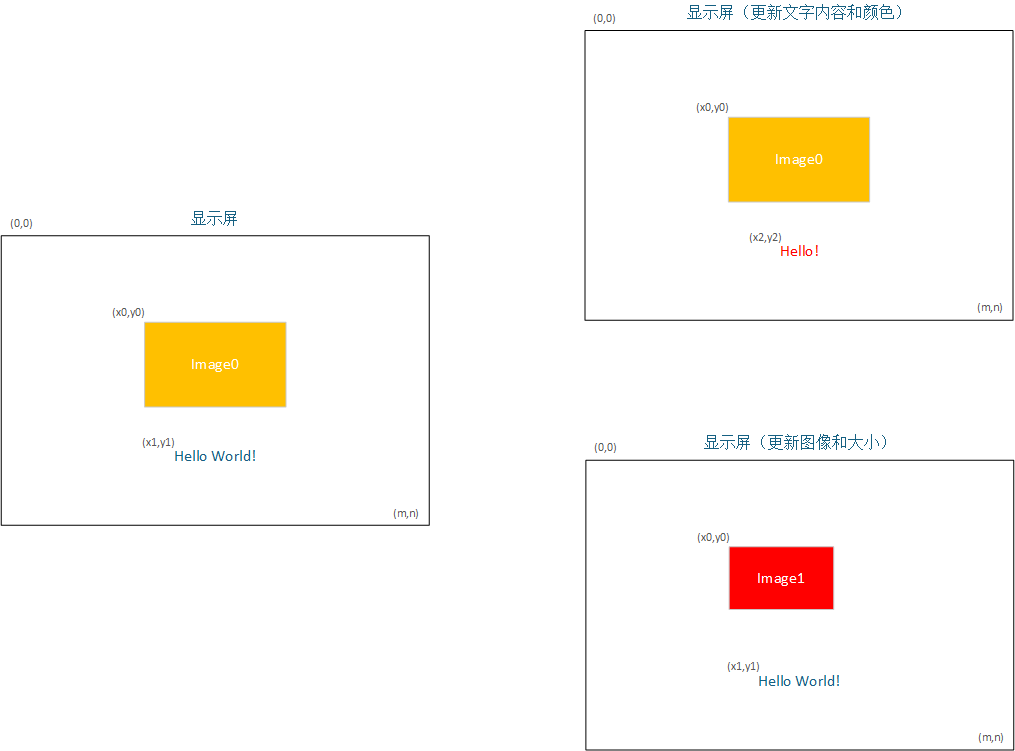
但如果界面需要频繁更新,问题就出现了。文字、图标或局部内容一旦变化,往往需要清除旧区域,再重新向新坐标写入数据。
动态刷新需求¶
当屏幕内容不再是一成不变,而是需要由状态机持续管理和刷新时,直接依赖显示器芯片显存会逐渐变得难以维护。对于简单局部变化,这种方式还能勉强应对;但当 UI 结构变复杂后,局限会越来越明显。
带透明通道图片叠加¶
如果只是单张不透明图片,直接写入即可;如果图片带 Alpha 通道,情况就不同了。
没有背景时,
Alpha=0xFF直接使用前景像素,Alpha=0x00不绘制,中间值做混合即可。有背景且背景不是纯色时,必须先拿到背景像素,再与前景图像做混合。
这意味着主控侧需要缓存背景色,否则无法正确完成透明图层叠加。
字体本质上也是类似的情况。带抗锯齿效果的字体通常也包含透明通道,最终显示效果取决于字体像素与背景色的混合结果。

页面滑动需求¶
如果进一步出现页面滑动、惯性滚动、转场动画等需求,而且页面中还包含透明图片和复杂控件,那么单纯依赖显示器显存就很难优雅实现了。虽然理论上仍可以由主控自己计算,但从复杂度和可维护性来看,通常都需要引入中间缓存。

部分帧缓存 PFB(Partial Frame Buffer)¶
一个直觉上的办法,是在主控里做完整帧缓存。但这在嵌入式场景里往往不现实。
例如一个 320x240 的 RGB565 屏幕,完整帧缓存需要:
320 * 240 * 2 = 153600B = 150KB
对很多 MCU 来说,这已经接近甚至超过可用 RAM 总量。
PFB 的思路,就是只分配一小块缓冲区,分块渲染屏幕内容,再把每块结果刷到显示器上。这样既能保留较灵活的绘制模型,又不用承担完整帧缓存的 RAM 代价。
本项目的 PFB 机制支持任意尺寸配置,哪怕只有 8x8 大小,也仍然可以驱动完整屏幕。更关键的是,应用层 API 不需要关心 PFB 的具体大小,框架会负责把渲染拆分成多个局部块。
通过配置 EGUI_CONFIG_PFB_WIDTH 和 EGUI_CONFIG_PFB_HEIGHT 就可以指定 PFB 尺寸。
PFB 刷新机制¶
屏幕刷新时,框架会从 (0, 0) 坐标开始,按既定扫描顺序覆盖整个屏幕。每次只计算当前 PFB 区域需要显示的内容,再通过显示驱动将该区域结果写回显示器。
只有真正发生变化的区域才会参与刷新,这里会结合脏矩形机制一起工作,从而显著降低整体刷新成本。
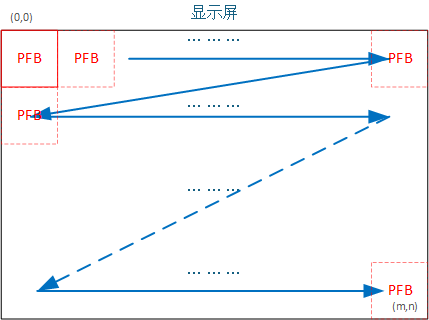
核心遍历逻辑位于 egui_core_draw_view_group()。对于每个脏矩形区域,框架会计算需要多少个 PFB 分块覆盖该区域,然后逐块执行以下流程:
初始化当前分块对应的 canvas
清空当前 PFB
绘制视图树
提交该块到显示硬件
// 伪代码:PFB 分块遍历
for (y = 0; y < pfb_height_count; y++) {
for (x = 0; x < pfb_width_count; x++) {
egui_canvas_init(&core->canvas, core, pfb, ®ion); // 设置当前 PFB 区域
egui_api_pfb_clear(pfb, size); // 清空缓冲区
view_group->api->draw(view_group); // 绘制视图树
egui_core_draw_data(core, ®ion); // 提交到显示设备
}
}
PFB 实现机制¶
本项目底层图像绘制统一通过 egui_canvas_t 完成。egui_canvas_t 会维护当前 PFB 指针(egui_color_int_t *pfb)以及当前 PFB 对应的区域信息(egui_region_t pfb_region)。
最终大多数绘制流程都会落到 egui_canvas_draw_point() 这一类底层接口。绘制时会先判断目标像素是否落在当前 PFB 覆盖范围内;如果在,则换算成 PFB 内部坐标,再写入或混合到对应像素。
void egui_canvas_draw_point(egui_dim_t x, egui_dim_t y, egui_color_t color, egui_alpha_t alpha)
{
egui_canvas_t *self = &canvas_data;
...
if (egui_region_pt_in_rect(&self->base_view_work_region, x, y))
{
egui_dim_t pos_x = x - self->pfb_location_in_base_view.x;
egui_dim_t pos_y = y - self->pfb_location_in_base_view.y;
egui_color_t *back_color = (egui_color_t *)&self->pfb[pos_y * self->pfb_region.size.width + pos_x];
if (alpha == EGUI_ALPHA_100)
{
*back_color = color;
}
else
{
egui_rgb_mix_ptr(back_color, &color, back_color, alpha);
}
}
}
因此应用层无需显式处理“当前是不是在局部缓冲里”,只需要按正常方式在 canvas 上绘制即可,canvas 会在最后一步完成裁剪、坐标转换和像素混合。
PFB 尺寸选择指南¶
PFB 的宽度和高度可以任意配置,但合理的选择能在 RAM 占用和性能之间取得更好的平衡。
配置原则¶
PFB 总像素数 = PFB_WIDTH * PFB_HEIGHT,这直接决定 RAM 占用。
PFB 宽度尽量接近屏幕宽度,这样每次覆盖的横向范围更大,
WriteRegion调用次数更少。PFB 高度至少建议达到屏幕高度的 1/10,否则线段、圆弧、圆角等图形在多次分块中会产生明显额外开销。
PFB 尺寸不要求一定是屏幕尺寸的整数约数,框架会自动处理边界块。
推荐配置表¶
屏幕分辨率 |
PFB 配置 |
PFB 像素数 |
RAM 占用 (RGB565) |
适用场景 |
|---|---|---|---|---|
128x128 |
128x16 |
2048 |
4 KB |
小屏手表,极低 RAM |
240x240 |
240x24 |
5760 |
11.25 KB |
圆形手表屏 |
240x320 |
240x32 |
7680 |
15 KB |
常见 TFT 屏,推荐配置 |
240x320 |
24x32 |
768 |
1.5 KB |
极限低 RAM,性能会明显下降 |
320x480 |
320x32 |
10240 |
20 KB |
大屏 TFT |
480x320 |
480x20 |
9600 |
18.75 KB |
横屏大屏 |
配置示例¶
在 app_egui_config.h 中配置:
// 推荐配置:240x320 屏幕,15KB PFB
#define EGUI_CONFIG_PFB_WIDTH 240
#define EGUI_CONFIG_PFB_HEIGHT 32
// 极限低 RAM 配置:仅 1.5KB
#define EGUI_CONFIG_PFB_WIDTH 24
#define EGUI_CONFIG_PFB_HEIGHT 32
双缓冲与多缓冲机制¶
单缓冲工作模式¶
默认情况下,系统使用单缓冲模式:CPU 渲染一个 PFB 分块,然后通过 SPI 把它发送到显示屏;发送完成后再渲染下一个分块。此时 CPU 和 SPI 基本是串行工作的。
CPU: [渲染PFB0][等待SPI][渲染PFB1][等待SPI][渲染PFB2][等待SPI]
SPI: [ 空闲 ][发送PFB0][ 空闲 ][发送PFB1][ 空闲 ][发送PFB2]
双缓冲工作模式¶
如果启用双缓冲或多缓冲,CPU 可以在 DMA 发送当前分块的同时,开始渲染下一个分块,从而实现渲染与传输并行。
CPU: [渲染PFB0][渲染PFB1][渲染PFB2][渲染PFB3]...
DMA: [ 空闲 ][发送PFB0][发送PFB1][发送PFB2]...
这种流水线方式通常能显著提高帧率,尤其适合 SPI 发送时间和 CPU 渲染时间接近的场景。
PFB Manager 环形缓冲队列¶
当前多缓冲由 egui_pfb_manager_t 统一管理。推荐方式是使用编译期声明的 PFB 数组,并直接交给 egui_init():
EGUI_CONFIG_PFB_BUFFER_DECLARE(egui_pfb);
static egui_core_t core;
void app_main(void)
{
egui_init(&core, egui_pfb);
}
如果是子屏幕或运行时确定尺寸的场景,也可以显式传入 PFB 数组,使用 egui_init_display():
egui_color_int_t *pfb_bufs[] = { pfb0, pfb1, pfb2 };
egui_init_display(
&core,
screen_w,
screen_h,
pfb_bufs,
3,
pfb_w,
pfb_h
);
egui_pfb_manager_t 内部会维护渲染队列和发送队列,应用层不需要再手动切换“主 PFB / 备份 PFB 指针”。
SPI 总线共享¶
如果 LCD 和外部 Flash 共用同一条 SPI 总线,可以通过总线锁机制避免冲突:
egui_pfb_bus_acquire(&core); // 暂停 PFB flush,获取总线使用权
// ... 读写外部 Flash ...
egui_pfb_bus_release(&core); // 释放总线,恢复 flush
总线锁定期间,CPU 仍可继续渲染,结果会暂存在 PFB 队列中;释放后再继续发送。
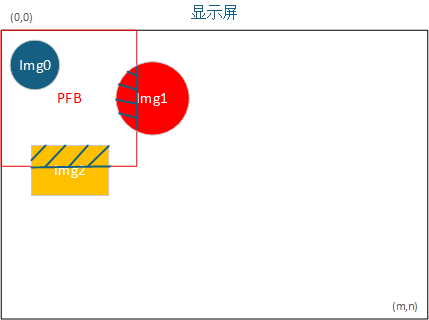
PFB 性能分析¶
PFB 的本质是“用时间换空间”。PFB 越小,RAM 占用越低,但渲染和提交分块的次数也会越多,因此刷新速度会下降。
本项目对基础图形做了较完整的二次裁剪,尽量减少“明明不在当前 PFB 区域里、却依然参与计算”的无效开销,以便在小 PFB 场景下仍保持可接受性能。
如下图所示,理想情况下只让真正落在当前区域内的部分参与绘制,可以有效减少 CPU 浪费。
PFB 不同尺寸测试¶
项目在设计阶段就针对“小 PFB”场景做了专项性能测试,用于评估不同尺寸下 CPU 的绘制代价。建议在真实 MCU 或 QEMU 环境中测试,不建议直接用 PC 模拟器数据作为性能基准。
以 HelloPerformance 为例,可以在 stm32g0 平台运行:
make run APP=HelloPerformance PORT=stm32g0
EGUI_CONFIG_PFB_WIDTH 和 EGUI_CONFIG_PFB_HEIGHT 可按需调整。
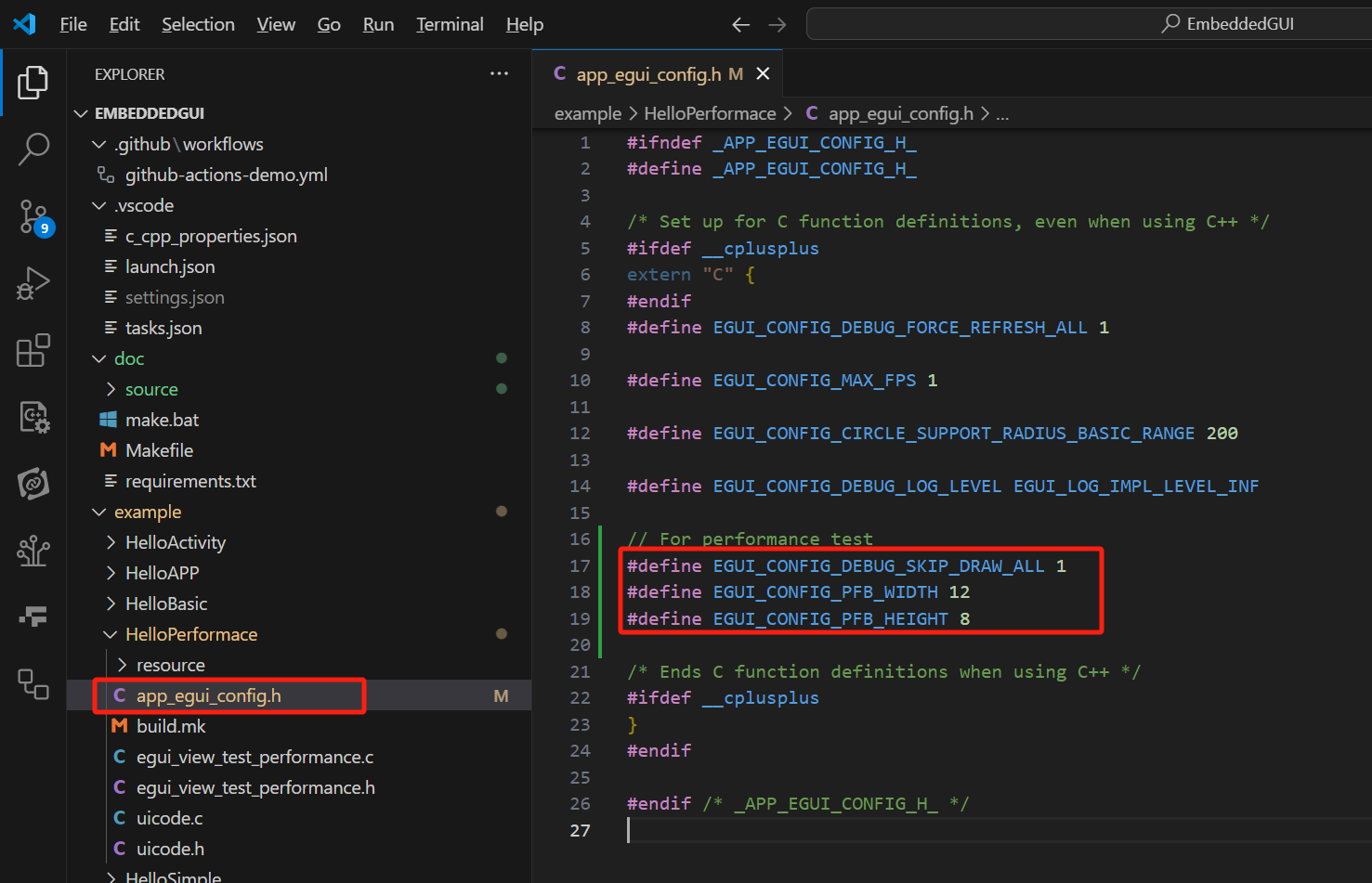
测试统计结果如下。以 24x32 为例,这类“宽高约为屏幕十分之一”的配置,在很多基础图形场景下已经能取得不错的平衡。
场景 |
12x8 |
24x32 |
240x32 |
24x320 |
|---|---|---|---|---|
LINE |
104.8ms |
21.6ms |
10.7ms |
9.6ms |
IMAGE_565 |
49.1ms |
27.4ms |
23.6ms |
24.8ms |
TEXT |
92.1ms |
19.5ms |
12.5ms |
17.1ms |
TEXT_RECT |
135.0ms |
24.8ms |
13.0ms |
17.6ms |
RECTANGLE |
40.7ms |
15.7ms |
12.3ms |
12.6ms |
CIRCLE |
135.4ms |
93.8ms |
84.8ms |
89.1ms |
ARC |
122.3ms |
51.0ms |
36.3ms |
42.4ms |
ROUND_RECTANGLE |
138.8ms |
96.0ms |
86.7ms |
91.2ms |
RECTANGLE_FILL |
37.7ms |
18.0ms |
15.1ms |
15.6ms |
CIRCLE_FILL |
387.3ms |
63.5ms |
23.5ms |
25.6ms |
ARC_FILL |
212.5ms |
121.0ms |
108.4ms |
108.1ms |
ROUND_RECTANGLE_FILL |
391.4ms |
66.5ms |
26.0ms |
28.4ms |
性能分析要点¶
从上面的数据可以提炼出几条结论:
PFB 从
12x8增大到24x32时,性能提升最明显。这是因为极小 PFB 会造成大量分块遍历和重复裁剪开销。PFB 从
24x32增大到240x32后,边际收益开始递减。对很多项目来说,24x32已经是不错的性价比平衡点。圆形、圆角矩形这类需要逐像素判断的图形,对 PFB 尺寸最敏感。PFB 过小时,同一个图形会被拆成很多块重复参与运算。
图片绘制对 PFB 尺寸通常没那么敏感,因为图片往往以行扫描为主,裁剪效率较高。
更完整的数据和分析可以参考性能测试章节。
提示:性能测试应在 QEMU 或真实 MCU 上进行。PC 模拟器计时精度通常只有 1ms,不适合作为严肃性能基准。
PFB 形状对性能的影响¶
除了总面积,PFB 的形状也会显著影响性能。为量化这一点,项目对 240x240 屏幕做了多种 PFB 形状测试:
配置名 |
PFB 尺寸 |
总像素数 |
特点 |
|---|---|---|---|
small |
15x15 |
225 |
小块,宽高均为屏幕的 1/16 |
middle |
30x30 |
900 |
中等块,宽高均为屏幕的 1/8 |
fullwidth |
240x1 |
240 |
全宽单行 |
fullheight |
1x240 |
240 |
全高单列 |
fullscreen |
240x240 |
57600 |
全屏缓冲,作为理论上限参考 |
完整热力图如下:

结合 PFB 矩阵测试报告,可以得到如下结论。
1. 全高单列(1x240)通常是最差的形状¶
虽然 fullheight(1x240) 和 fullwidth(240x1) 总像素数相同,但全高单列在绝大多数场景下都显著更慢。原因在于很多图形算法天然更适合按“行”处理,而不是按“列”处理。
测试用例 |
fullwidth (240x1) |
fullheight (1x240) |
性能差距 |
|---|---|---|---|
ELLIPSE |
4.970 ms |
177.934 ms |
36 倍 |
ELLIPSE_FILL |
2.198 ms |
116.474 ms |
53 倍 |
GRADIENT_ROUND_RECT_RING |
8.147 ms |
1351.166 ms |
166 倍 |
POLYGON_FILL |
2.730 ms |
73.558 ms |
27 倍 |
TRIANGLE_FILL |
2.036 ms |
42.931 ms |
21 倍 |
TEXT |
16.127 ms |
14.931 ms |
少数情况下接近 |
2. 中等方块(30x30)已接近全屏性能¶
30x30 的 PFB 仅占用约 1.8KB RAM,但多数图形操作已经能逼近全屏缓冲效率,是低 RAM 场景中很实用的折中。
测试用例 |
middle (30x30) |
fullscreen (240x240) |
倍数 |
|---|---|---|---|
RECTANGLE |
0.943 ms |
0.719 ms |
1.3x |
CIRCLE_FILL |
1.960 ms |
1.202 ms |
1.6x |
IMAGE_565 |
0.855 ms |
0.613 ms |
1.4x |
TEXT |
2.456 ms |
0.385 ms |
6.4x |
ARC_FILL |
5.491 ms |
4.753 ms |
1.2x |
3. PFB 形状选择建议¶
首选:宽度接近屏幕宽度的矮条,例如
240x32次选:接近正方形的小块,例如
30x30避免:全高单列或极窄高条,例如
1x240、2x120
经验上,在总像素数相同的前提下,PFB 越“宽”通常越有利于性能。
总结¶
PFB 是 EmbeddedGUI 的核心设计之一,它通过以下机制让低 RAM 设备也能实现较完整的 GUI 能力:
支持任意大小 PFB,适配极低内存场景
对应用层隐藏 PFB 细节,统一通过 canvas 绘制
结合脏矩形与二次裁剪,减少无效计算
支持双缓冲和多缓冲,提升渲染流水线效率
在有限 RAM 下依然保留较好的图像、文字和动画表现
实际项目中,建议先从“屏幕宽度的 1/10 到 1/4”这一量级开始尝试 PFB 尺寸,再根据性能测试结果逐步调优。